A team at Stanford University in the US has developed a benchmark for machine learning in chemistry. By providing a consistent way to test different techniques across a range of chemical data, it aims to accelerate the growth of this new type of scientific problem-solving.
Source: Royal Society of Chemistry
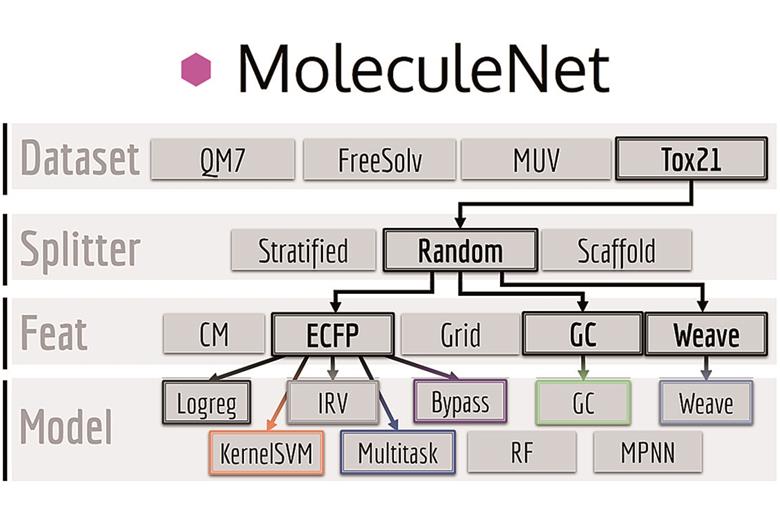
MoleculeNet curates multiple public datasets, establishes metrics for evaluation, and offers high quality open-source implementations of multiple previously proposed molecular featurisation and learning algorithms (released as part of the DeepChem open source library)
Machine learning methods train a computer to efficiently get from raw data to already-known answers. Once the expected results are consistently reproduced, the software is ready to perform the same task with entirely new data. To fairly compare different learning approaches, research groups around the globe need to train and test their methods using a shared set of problems. Reference databases already exist for images and text; MoleculeNet, an extension of the DeepChem project, provides such a benchmark for chemistry.
Read the full story by Alexander Whiteside on Chemistry World.








")